国际声学、语音与信号处理会议(International Conference on Acoustics, Speech and Signal Processing,ICASSP),是语音信号处理领域顶级国际会议(CCF推荐B类国际会议),每一年举办一次。ICASSP 2025 将于 2025 年 4 月 6 日至 11 日在印度海得拉巴举行。
蒙古文智能信息处理技术国家地方联合工程研究中心共有12篇语音相关领域论文被ICASSP 2025主会议录用,研究内容涵盖语音生成、语音合成、声源定位、回声消除、多通道语音增强、空间音频处理、低资源翻译、事件抽取等,以下为论文简述。
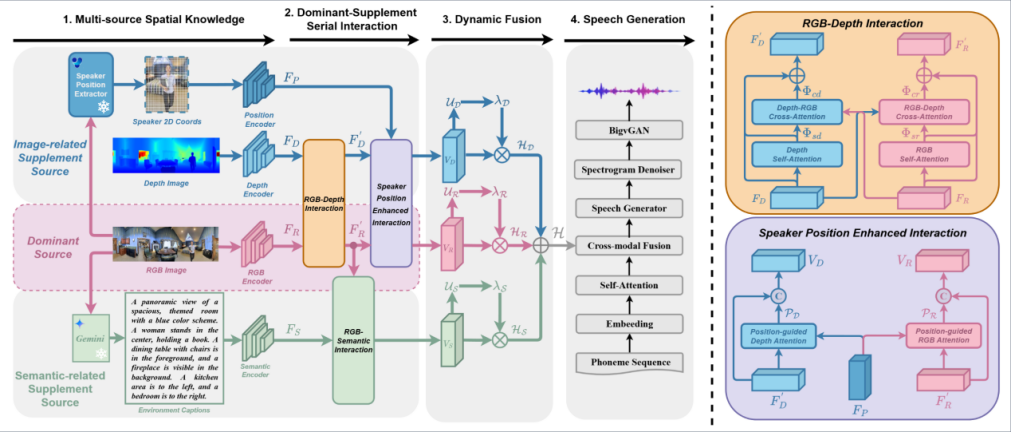
Multi-Source Spatial Knowledge Understanding for Immersive Visual Text-to-Speech
作者:何树伟,刘瑞*
单位:内蒙古大学
摘要:视觉文本转语音 (VTTS) 旨在利用环境图像作为提示,来合成具有真实环境混响效果的语音内容。以往的研究主要局限于使用 RGB 图像进行全局环境建模,未能充分利用深度信息、说话者位置以及环境语义等多维度空间信息。针对这一问题,我们提出了一种创新的多源空间知识理解方案,用于提升沉浸式 VTTS 效果,命名为 MS²KU-VTTS。在该方案中,我们将 RGB 图像设定为主要信息源,同时引入深度图像、基于目标检测的说话者位置信息以及由 Gemini 生成的场景语义描述作为辅助信息源。我们设计了一种串行交互机制,实现主要信息源与辅助信息源的有效融合。系统会根据各个信息源的重要程度,动态整合多源知识。这种多源空间知识的深度交互与融合为语音生成模型提供了更全面的指导,显著提升了语音的沉浸感。实验结果证实,MS²KU-VTTS 在生成沉浸式语音方面的表现优于现有方法。
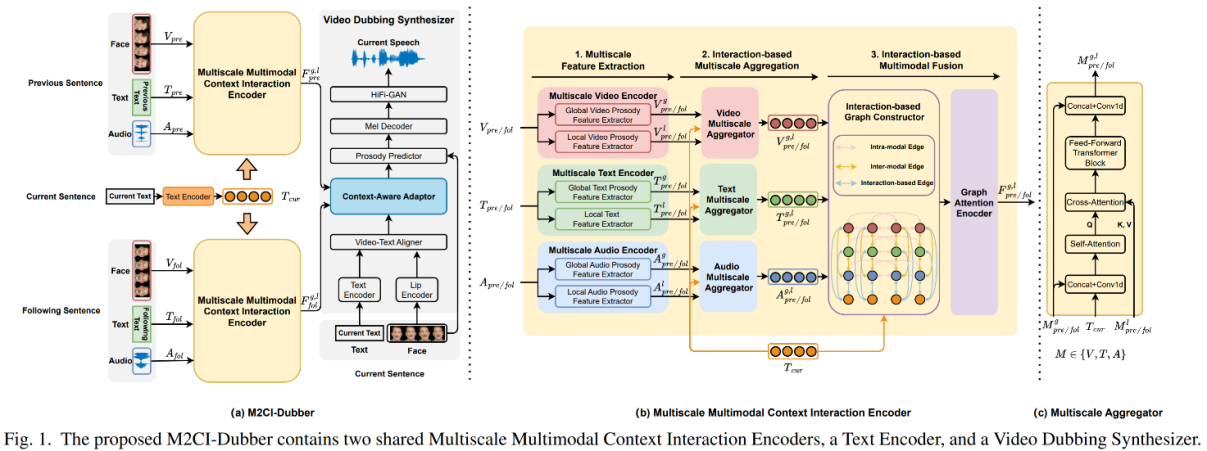
Towards Expressive Video Dubbing with Multiscale Multimodal Context Interaction
作者:赵源1,刘瑞1*,丛高翔2
单位:1内蒙古大学,2中国科学院计算技术研究所
摘要:自动视频配音(Automatic Video Dubbing,AVD)从脚本中生成与嘴唇运动和面部情绪对齐的语音。最近的研究关注建模多模态上下文以增强韵律表达,但忽略了两个关键问题:1)上下文中的多尺度韵律表达属性影响当前句子的韵律。2)上下文中的韵律线索与当前句子互动,影响最终的韵律表达。为了解决这些挑战,我们提出了M2CI-Dubber,一种用于AVD的多尺度多模态上下文交互方案。该方案包括两个共享的M2CI编码器,用于建模多尺度多模态上下文并促进其与当前句子的深度交互。通过为上下文中的每种模态提取全局和局部特征,利用基于注意力机制的聚合和交互,并采用基于交互的图注意力网络进行融合,所提出的方法增强了合成语音的韵律表达,使其更适合当前句子。对Chem数据集上的实验证明,我们的模型在配音表现方面优于基线模型。
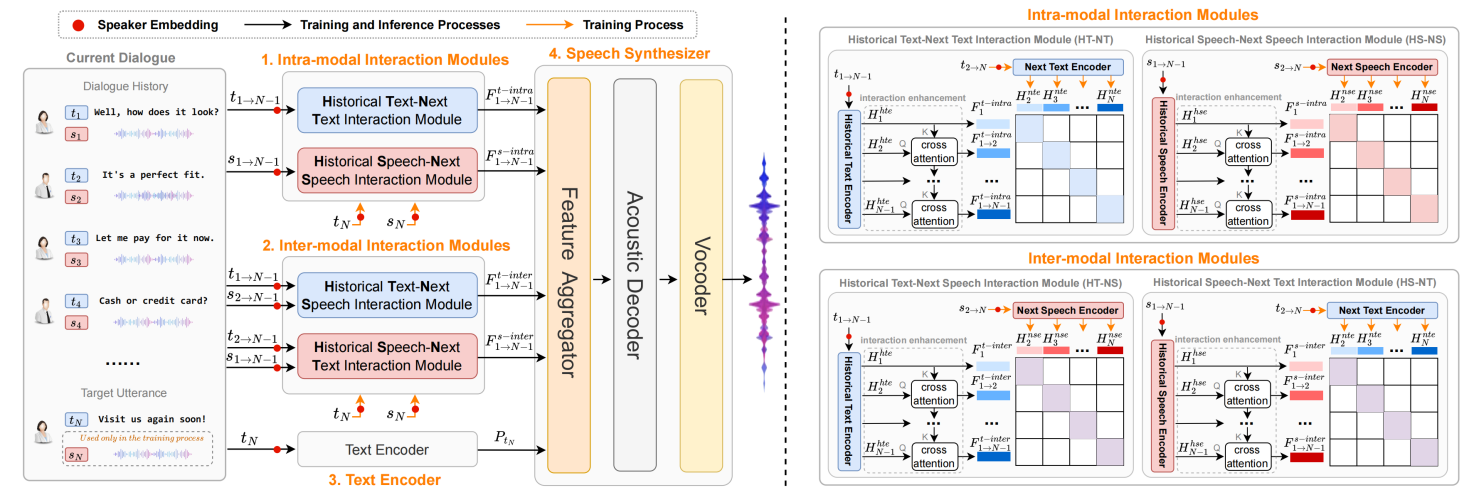
Intra- and Inter-modal Context Interaction Modeling for Conversational Speech Synthesis
作者:贾真琦,刘瑞*
单位:内蒙古大学
摘要:对话式语音合成(Conversational Speech Synthesis,CSS)旨在有效地利用多模态对话历史(Multimodal Dialogue History,MDH)生成具有适当会话语境的目标话语。CSS的关键挑战在于对MDH和目标话语之间的交互进行建模。需要注意的是,在MDH中,文本和语音模态具有独特的跨模态影响,同时它们又相互补充以对目标话语的表达产生综合影响。先前的研究没有显式建模这种模态内部和模态间的交互。为了解决这个问题,我们提出了一种基于新的模态内和模态间上下文交互方案的CSS系统,称为I3-CSS。具体来说,在训练阶段,我们将MDH与目标话语中的文本和语音模态相结合,得到四种模态组合,包括“历史文本-下一个文本”,“历史语音-下一个语音”,“历史文本-下一个语音”和“历史语音-下一个文本”。然后,我们设计了两个基于对比学习的模态内交互和两个模态间交互模块,以深入学习模态内和模态间的上下文交互。在推理阶段,我们使用MDH并采用训练好的交互模块来充分推断目标话语文本内容的语音韵律。在DailyTalk数据集上进行的主观和客观实验表明,I3-CSS在韵律表达方面优于先进的基线模型。
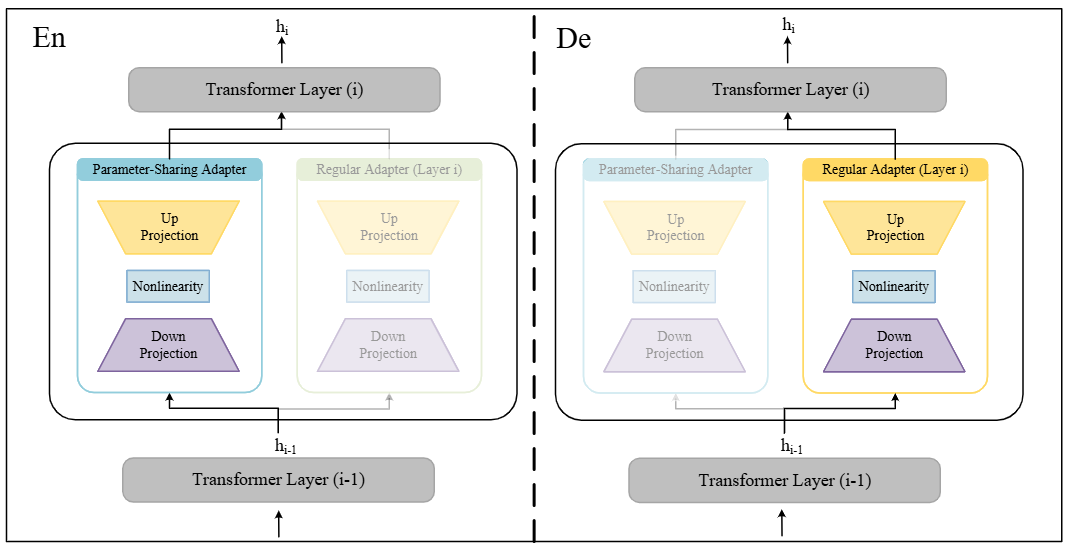
Multilingual Parameter-Sharing Adapters: A Method for Optimizing Low-Resource Neural Machine Translation
作者:张云龙+,陈楠+,王勇和,苏向东,飞龙*
单位:内蒙古大学
摘要:基于适配器的多语言神经机器翻译(MNMT)通过减轻高资源和低资源语言对之间的数据不平衡并降低训练成本,已成为低资源语言翻译的重要方法。然而,现有的基于适配器的方法缺乏跨语言环境的泛化,特别是在资源匮乏的情况下,其可扩展性受到限制。此外,当前的方法通常为每种语言引入独立的适配器模块,导致模型参数随着语言数量的增加而线性增加。为了应对这些挑战,我们提出了一种多语言参数共享适配器方法。此外,我们引入了基于神经架构搜索(NAS)的策略来提高翻译性能。实验结果表明,多语言参数共享适配器在低资源和高资源数据集上都表现出有竞争力的性能。多语言参数共享适配器方法只有400K个可训练参数,比传统适配器方法的参数减少了20倍。
+:equal contribution
Enhancing Multi-Channel Speech with Limited Microphones via Spherical Harmonic Transform
作者:潘佳慧,张晖,张学良*
单位:内蒙古大学
摘要:传统波束形成算法的性能依赖于麦克风数量,通常随着麦克风数量的增加,性能得以提升。然而,在实际应用中,麦克风的数量往往是有限的。为此,本文提出了一种创新的虚拟麦克风估计方法,该方法结合了传统波束形成技术与基于神经网络的球谐变换(SHT)方法的优势,克服了各自的局限性。具体而言,我们的方法通过预测虚拟麦克风位置的SHT系数,并将其反变换为虚拟语音信号,从而有效地利用球谐域中的空间信息,提升虚拟麦克风估计的准确性和效率。针对开放的MS-SNSD数据集进行的评估结果表明,所提出的方法在性能上明显优于现有基准方法。算法描述如下:

Robust Target Speaker Direction of Arrival Estimation
作者:李子轩1,何树林2,张学良1,*
单位:内蒙古大学
摘要:在复杂的多说话人环境中,准确估计目标说话人的波达方向(DOA)对于增强语音清晰度和分离目标语音至关重要。然而,传统的DOA估计技术在噪声和混响的影响下表现欠佳,且在存在干扰说话人时容易失效。为了克服这些挑战,我们提出了一种鲁棒的实时DOA估计系统——RTS-DOA。该系统融合了语音增强、说话人特征建模和空间信息建模技术。具体来说,RTS-DOA系统由三个核心模块构成:首先是语音增强模块,它负责提升语音信号的质量;其次是空间信息模块,它负责捕捉和学习环境中的空间特性;最后是说话人特征提取模块,它专注于识别和提取目标说话人的独特特征。通过这些模块的协同工作,RTS-DOA系统能够有效地处理多说话人场景中的语音信号。我们在LibriSpeech数据集上进行的实验表明,RTS-DOA系统在处理多说话人场景时表现出色,相较于同等计算资源的基线模型,其性能提升了约30%。
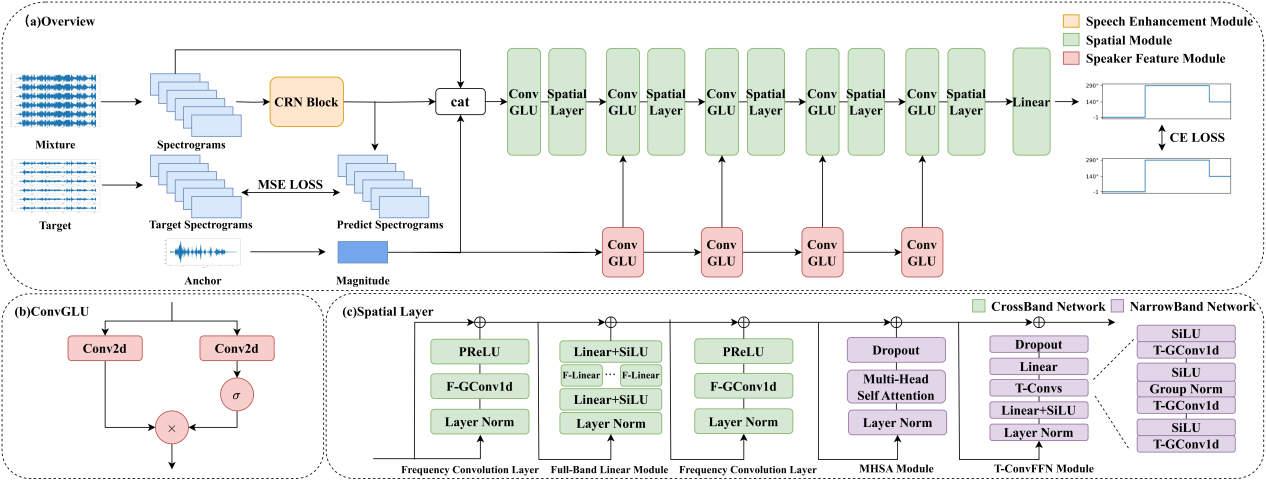
Attention-Based Beamformer For Multi-Channel Speech Enhancement
作者:白景霖,李号,张学良*,陈霏
单位:1内蒙古大学,南方科技大学
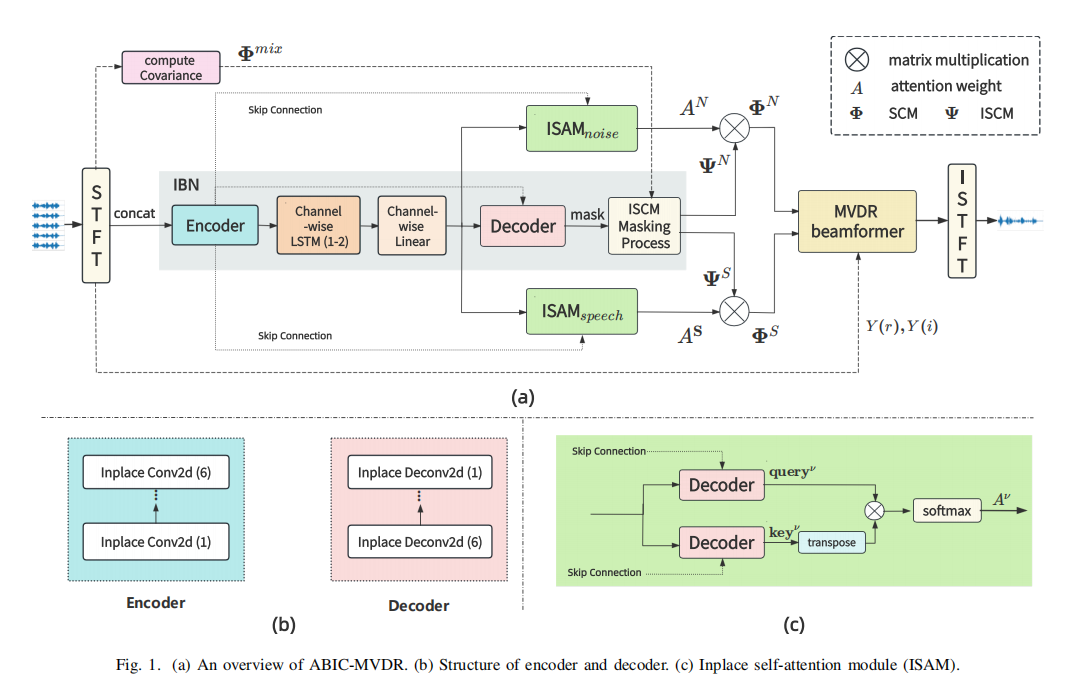
摘要:多通道语音增强使用多个捕获空间线索的麦克风来提取语音,对于视频会议系统、远程通信和助听器等应用至关重要。最小方差无失真响应(MVDR)是一种经典的自适应波束形成器,理论上可以确保信号在目标方向上无失真传输,这使得它在实际应用中很受欢迎。MVDR的降噪性能实际上取决于噪声和语音空间协方差矩阵(SCM)估计的准确性。然而,大多数基于掩模的波束形成方法通常假设源是静止的,忽略了移动源的情况,这会导致性能下降。在本文中,我们提出了一种基于注意力机制计算语音和噪声SCM的方法,再应用MVDR来获得增强后的语音。为了充分利用空间信息,我们应用了原地卷积算子和频率无关的LSTM来改进对SCM估计。实验表明,在各种条件下,我们所提出的方法在计算量减少、参数减少的情况下优于其他基线。
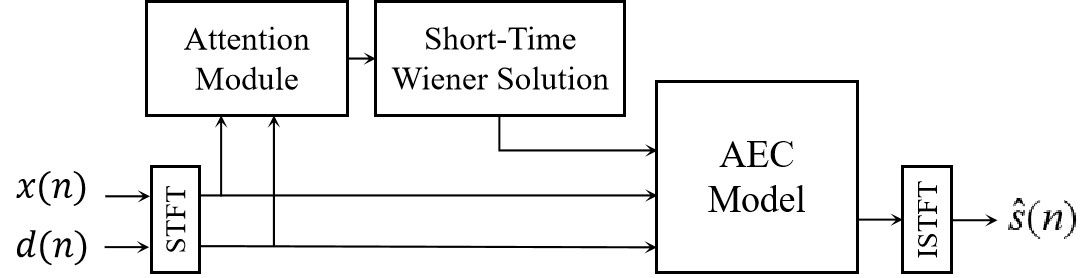
Attention-Enhanced Short-Time Wiener Solution for Acoustic Echo Cancellation
作者:赵飞,张学良*
单位:内蒙古大学
摘要:声学回声消除 (AEC) 是一种重要的语音信号处理技术,可消除麦克风输入中的回声,从而实现自然的全双工通信。目前,基于深度学习的 AEC 方法主要侧重于改进模型架构,经常忽略传统滤波器理论知识的结合。本文通过引入注意力增强的短时维纳解决方案,提出了一种创新的 AEC 方法。我们的方法策略性地利用注意力机制来减轻双讲干扰的影响,从而优化知识利用效率。短期维纳解的推导将经典维纳解应用于有限输入因果关系,将滤波器理论的既定见解整合到该方法中。实验结果证实了我们提出的方法的有效性,在性能和泛化方面超越了其他基线模型。
Vector Quantized Diffusion Model Based Speech Bandwidth Extension
作者:方元,白景霖,王佳杰,张学良*
单位:内蒙古大学,商汤科技
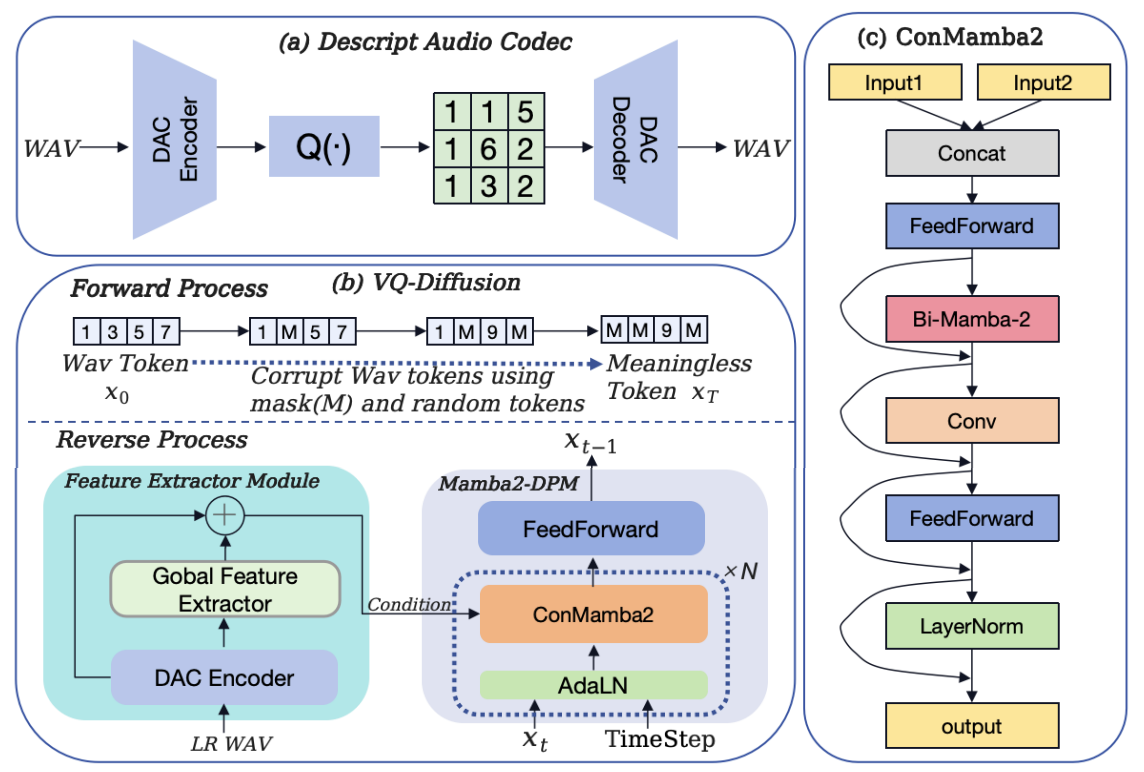
摘要:神经网络音频编解码器的最新进展为音频信号处理解锁了新的潜力。研究越来越多地探讨如何利用神经网络音频编解码器的潜在特征来完成各种语音信号处理任务。本文首次提出了一种基于神经网络音频编解码器离散特征的语音带宽扩展方法。通过在高度压缩的离散编码中恢复高频细节,该方法显著增强了语音的可懂度和自然度。基于向量量化扩散模型,所提出的框架结合了先进的神经网络音频编解码器、扩散模型以及Mamba-2的优势,重建语音高频成分。大量实验表明,该方法在对数频谱距离和ViSQOL指标上均表现出卓越的性能,显著提升了语音质量。
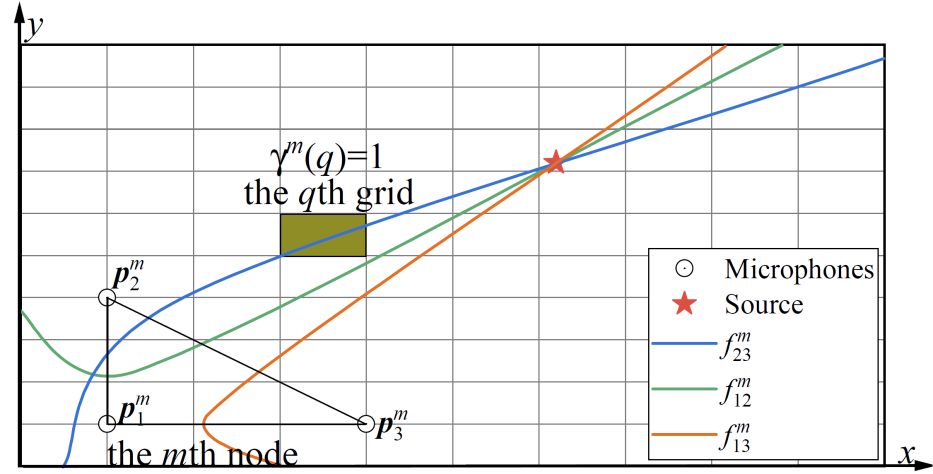
Distributed-Robust Source Localization in Wireless Acoustic Sensor Networks
作者:王旭,呼德*,斯琴图雅
单位:内蒙古大学
摘要:在本文中,我们提出了一种无线声学传感器网络(wireless acoustic sensor networks, WASNs)中的分布式鲁棒声源定位(distributed-robust sound source localization, D-R-SSL)方法。具体而言,首先将空间划分为小的等大小网格,并通过使用节点间到达时间差(time difference of arrival, TDoA)来计算每个网格包含声源的局部概率。接下来,我们为来自不同节点的局部概率分配权重,并开发了一种鲁棒的分布式权重计算策略,以应对TDoA中的异常值。然后,声源位置通过局部概率的加权求和来推导。为了提高声源定位(SSL)的效率,我们进一步提出了一种快速实现方法(称为F-D-R-SSL)。最后,我们还分析了所提方法的计算复杂度和通信负载。仿真和实际实验表明,F-D-R-SSL在性能上与最先进的非网格SSL方法相当,甚至更强。
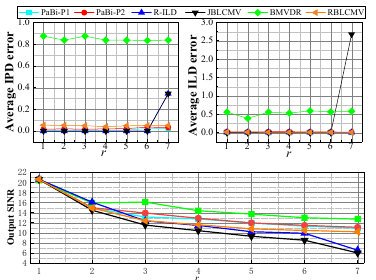
Parametric Binaural Beamforming based on Auditory Perception
作者:呼德*,张鑫喆
单位:内蒙古大学
摘要:由于助听器的内部空间限制,其只能装配少量麦克风(一般为2-4个麦克风)。这导致了双耳波束形成器(BF)中降噪和空间线索保持之间的冲突。为了缓解这种冲突,我们从听觉感知的角度设计了一个参数化双耳(PaBi)BF。在人类听觉中,双耳线索是频率选择性的,即耳间相位差(IPD)在低频占主导地位,而耳间电平差(ILD)在高频占主导地位。因此,我们构建了一组参数IPD和ILD约束来建立一个新的成本函数,然后通过半定松弛策略求解。通过调整相关参数,可以在降噪和空间线索保留之间实现良好的权衡。此外,PaBi BF突破了现有方法的自由度限制。实验结果表明了该方法的优越性。
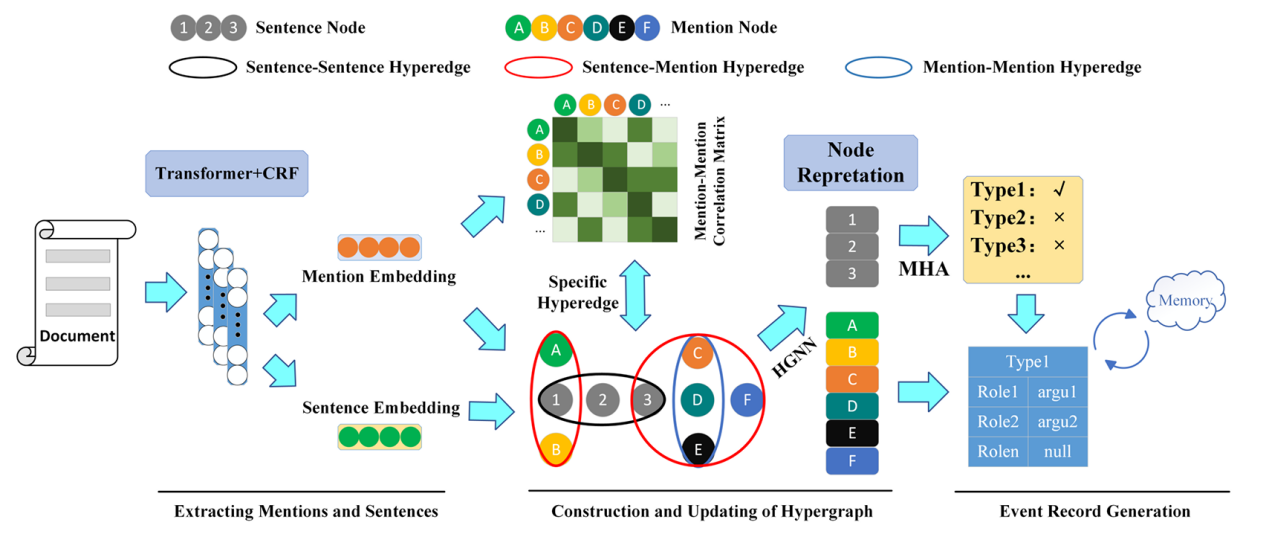
Dynamic Structure Hypergraph for Document-level Event Extraction
作者:任起,王炜华*,余杰,高光来
单位:内蒙古大学,国防科技大学
摘要:文档级事件提取(DEE)旨在识别给定文档中的事件信息。此任务的两个挑战是分散在不同句子中的事件论元和单文档中存在多事件。在本文中,我们提出了一种新的动态超图模型来解决传统图中全局建模能力有限的问题。首先,我们构建一个超图来建模文档中不同句子和实体之间的全局交互。然后,通过基于更新的节点表示构建提及-提及相关矩阵来生成新的超边,从而使超图具备动态结构。此方法允许根据上下文更新节点的语义。最后,广泛的实验和分析表明,我们的方法在应对上述两个挑战中取得了显著改进,并在两个公开数据集上的表现优于现有的最先进模型。