图像分割类应用(包括语义分割、实例分割、显著物体检测等)既要提取图像细节信息计算高质量分割掩码图,又依赖于图像的全局信息以实现场景识别。最近提出的基于视觉Transformer结构方法依靠自注意力机制的全局建模能力,显著提高了图像分割的准确率。但是视觉Transformer结构存在计算复杂度高、缺少细节信息等局限性,难以获得像素级分割结果。
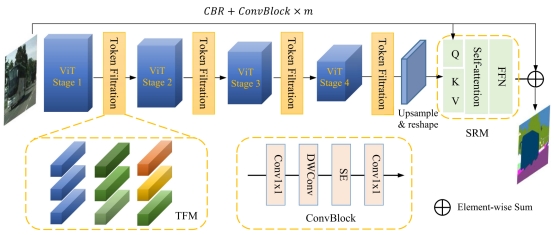
文章针对基于Transformer结构图像分割领域存在的上述问题,利用特征筛选方法,筛选出重要特征并增强重要特征在网络中的权重,解决了现有Transformer分割方法计算复杂,结果不够准确的问题。同时将Transformer特征与卷积神经网络特征融合,进一步精炼分割结果。实验结果表明,此方法在不同的图像分割数据集上都取得了显著的性能提升。
该研究得到了国家自然科学基金的资助,论文链接:https://ieeexplore.ieee.org/document/10474206

