音频深度伪造检测(ADD)旨在检测由语音合成(TTS),和语音转换(VC)等产生的假音频,近年来成为备受关注的一个新课题。传统工作读取单声道信号并直接分析伪影。最近,基于单耳到双耳转换的ADD方法越来越受到关注,因为双耳音频信号提供了一个独特而全面的语音感知视角。然而,来自两个声道的声学信息表现出差异和相似之处,这在以前的研究中没有被深入研究。
为了解决这个问题,该工作提出了一种新的基于单耳到双耳转换的ADD框架,该框架考虑了多空间声道表示学习,称为“MSCR-ADD”。具体来说,将声道特征表示空间分为“特定表示空间”、“共享表示空间”和“差异表示空间”。最后,来自不同空间的三种表示混合在一起,以最终完成深度伪造检测。在四个基准数据集上的实验结果表明,我们的MSCR-ADD优于现有的最先进方法。
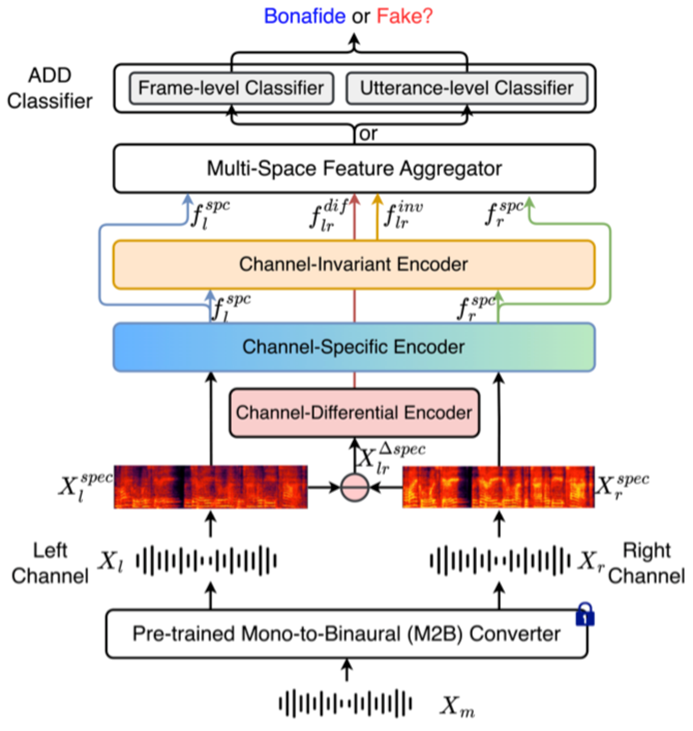
图1 MSCR-ADD模型架构图
相关论文《Multi-Space Channel Representation Learning for Mono-to-Binaural Conversion based Audio Deepfake Detection》发表在《Information Fusion》学术期刊。《Information Fusion》是国际计算机与人工智能、计算机与理论方法领域著名期刊之一,中科院JCR分区为一区Top期刊,影响因子为18.6。
内蒙古大学为论文唯一完成单位,论文作者包括:刘瑞研究员(第一作者),2022级硕士研究生 张锦华,高光来教授。这项研究得到了国家自然科学基金青年基金、内蒙古自治区“草原英才”、自治区留学人员创新创业启动支持计划、广东省数字孪生人重点实验室(华南理工大学)开放课题、内蒙古自治区本级引进高层次人才科研支持、内蒙古大学骏马计划高层次人才引进等项目的支持。
论文链接:https://www.sciencedirect.com/science/article/pii/S1566253524000356

