第 43 届国际机器学习大会(The 43rd International Conference on Machine Learning,ICML 2026)将于 2026 年 7 月 6 日至 7 月 11 日在韩国首尔举行。ICML 是机器学习与人工智能领域最具影响力的国际学术会议之一,是中国计算机学会 CCF 推荐的 A 类国际学术会议,也是国际计算机学科排名CSRankings列表会议。会议涵盖机器学习理论、算法、大模型、多模态学习及人工智能应用等前沿方向,集中展示机器学习领域的最新研究成果。我院苏向东教授课题组、曾俊桦博士的2篇论文被 ICML 2026 录用,相关研究分别聚焦长上下文大语言模型高效训练与推理、张量网络学习理论与方法。
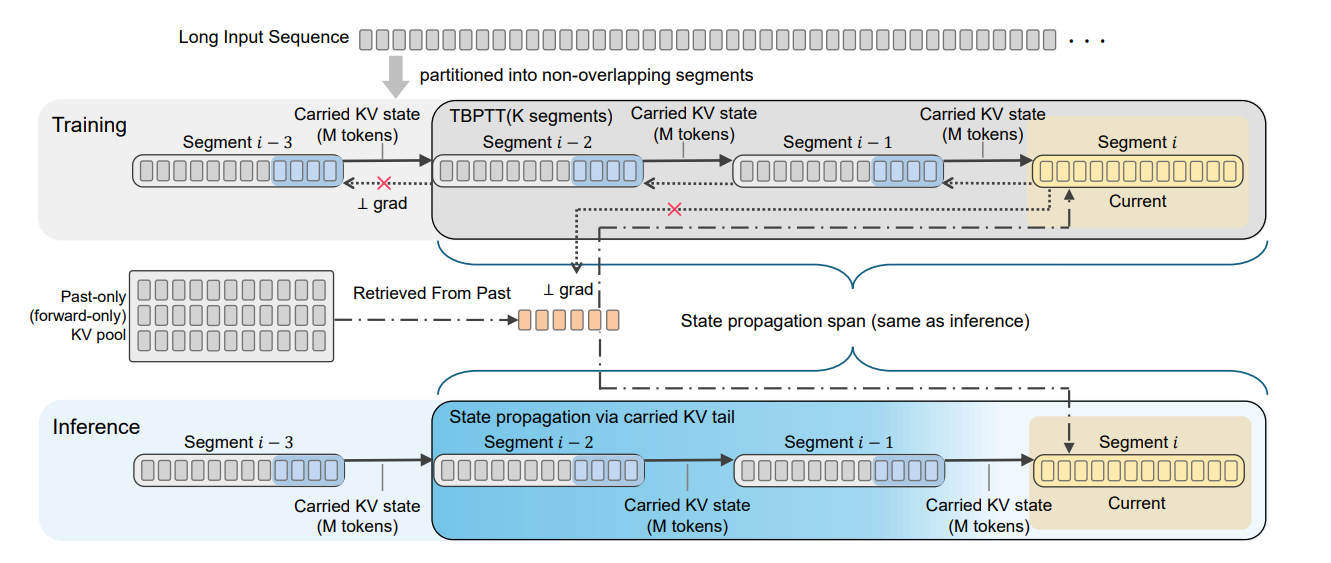
(1) Training–Inference Consistent Segmented Execution for Long-Context LLMs
作者: 尚贤鹏1, 李江1, 多泽华1, 蔡谦益2, 苏向东1*
1内蒙古大学计算机学院,2香港科技大学(广州)
长上下文生成对大语言模型的计算和显存效率提出了更高要求。现有许多高效长上下文方法通常只在推理阶段采用分段、窗口化或稀疏注意力等受限执行方式,而训练阶段仍依赖全上下文注意力,导致训练与推理过程不一致,影响模型在长上下文场景下的稳定性和泛化能力。针对这一问题,论文提出了一种训练—推理一致的分段生成框架,使模型在训练和推理阶段遵循相同的片段级执行方式,并通过受控的 KV 状态传递实现跨片段信息建模,同时以前向方式访问更远历史信息。实验结果表明,该方法在保持接近全上下文注意力性能的同时,有效降低了长上下文处理过程中的计算和显存开销,并在多个长上下文基准测试中展现出良好的性能与可扩展性,为高效长上下文大语言模型的训练与推理提供了新的解决思路。
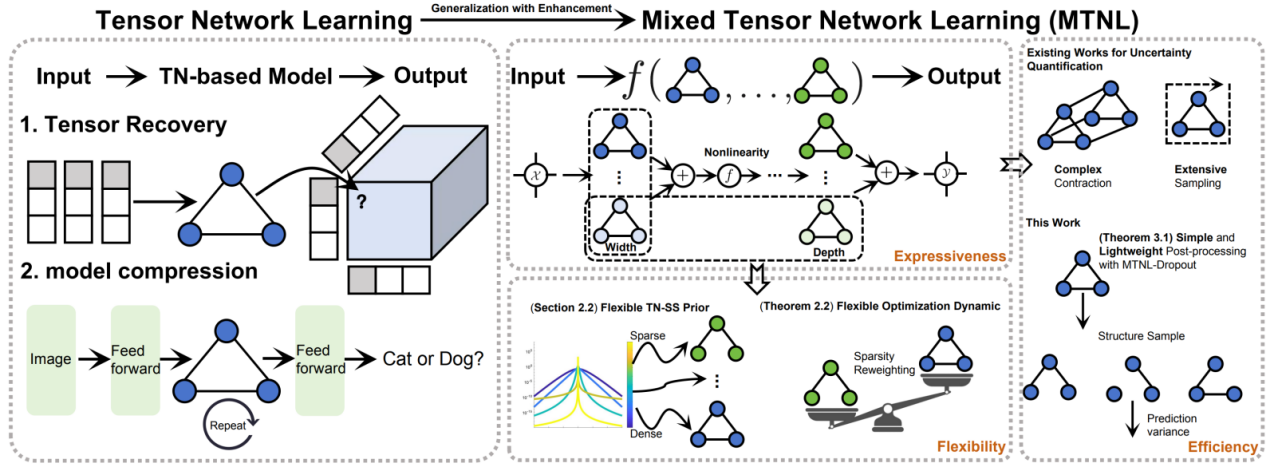
(2) MTNL: A Unified Modeling Perspective for Enhancing Tensor Network Learning
作者:曾俊桦1,邱育宁2,黎炳华3,李超2,赵启斌2,周郭许4
1 内蒙古大学计算机学院生成式机器学习实验室,2 日本理化学研究所,3 东京农工大学,4 广东工业大学
本研究工作提出了一种名为 MTNL(混合张量网络学习)的创新统一框架,旨在弥补张量网络在监督学习与非监督学习领域应用中长期存在的理论与应用鸿沟。为此,本工作试图从一个统一的建模视角出发,通过将多个张量网络以深度学习的层级风格进行融合,构建出一种具备强大表达能力的张量网络建模新范式。同时,MTNL通过引入一种基于广义逆高斯分布的贝叶斯先验,使得模型能够根据数据特征自动诱导出最优的张量网络结构,弥补了以往张量网络结构学习先验在学习多个张量网络结构时的理论缺陷。更进一步地,本文通过数学证明揭示了该框架的MAP解与Dropout优化机制之间的内在联系,进而开发出一种名为MTNL-Dropout的轻量化不确定性度量算法。相比于传统方法,该算法在保持不确定性度量精度的同时,将计算成本大幅降低了200倍以上。在实验验证环节,MTNL框架在多光谱图像恢复实验中的重建精度显著超越了主流基准;在大语言模型的参数高效微调任务中,该框架能够自动识别对性能影响关键的权重层,并自适应地分配张量网络结构。此外,该框架在面对数据分布偏移的回归任务中,能够有效地对不确定性进行建模。总体而言,MTNL在理论与实践层面为张量网络研究提供了一种新的视角。