国际计算语言学会议(International Conference On Computational Linguistics,COLING),是自然语言处理和计算语言学领域重要国际会议(CCF推荐B类国际会议),每两年举办一次。COLING 2025将于2025年1月19日至24日在阿联酋阿布扎比举行。
我院共有6篇长文被COLING 2025主会议录用,其中蒙古文智能信息处理技术国家地方联合工程研究中心(内蒙古自治区多语种人工智能技术重点实验室)5篇,生态大数据教育部工程研究中心1篇,研究内容涵盖知识图谱嵌入、对齐、文本生成及遥感图像解译等,以下为论文简述。
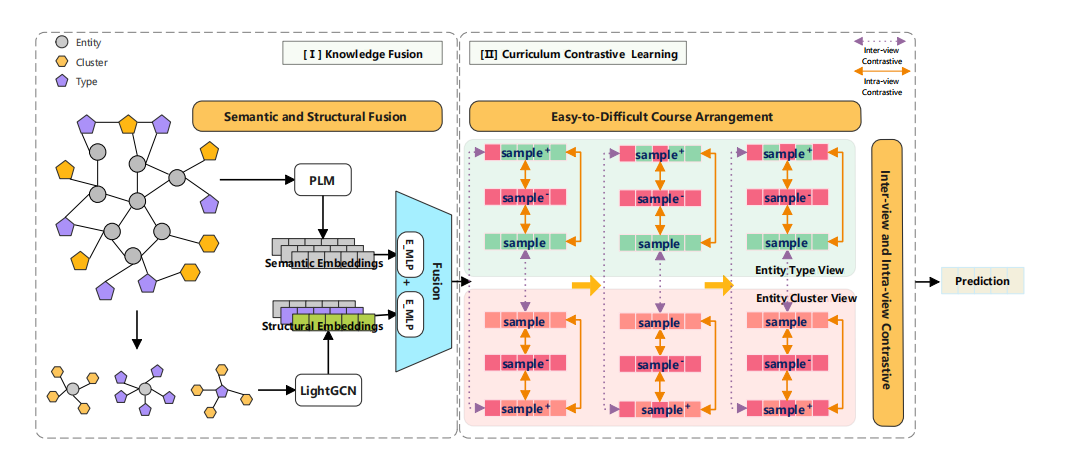
Knowledge Graph Entity Typing with Curriculum Contrastive Learning
作者:王浩,诺明花*,姜珊
单位:内蒙古大学
摘要:知识图谱实体类型补全(KGET)任务目标是补全知识图谱中实体缺失的类型。目前,大多数的研究只关注实体的结构信息或只关注实体的语义信息。在本文中,受到课程学习和对比学习的启发,提出了使用课程对比学习策略的CCLET模型来解决KGET任务,该模型利用预训练语言模型(PLM)和图模型分别融合知识图谱中与实体相关的语义信息和结构信息。本文提出的CCLET模型由两个主要部分组成。在知识融合部分,设计了一个增强的多层感知机(Enhanced-MLP)来融合实体的描述文本和相关的三元组;在课程对比学习部分,通过控制添加噪声的大小来定义课程的难度,并将课程学习与对比学习有机结合,采用课程对比学习策略从易到难逐步地学习特征,优化特征表示,从而提升整体性能。通过在数据集FB15kET和YAGO43kET上进行大量实验,验证了CCLET模型在KGET任务中的有效性。
Distance-Adaptive Quaternion Knowledge Graph Embedding with Bidirectional Rotation
作者:王炜华,梁秋雨,飞龙,高光来
单位:内蒙古大学
摘要:四元数由一个实部和三个虚部组成,为知识图谱嵌入提供了更具表达能力的空间。现有的四元数嵌入模型通过语义匹配或距离评分函数来衡量三元组的可信度。然而,我们发现语义匹配评分函数削弱了实体的可分离性,而距离评分函数则弱化了实体的语义。为了解决这个问题,我们提出了一种新的四元知识图嵌入模型,从实体的语义匹配和几何距离两个角度同时衡量每个三元组的可信度。具体来说,在四元数嵌入空间中,我们首先提出对头部实体进行右旋,对尾部实体进行反向旋转(双向旋转),以学习实体丰富的语义特征。然后,我们提出自适应的平移来学习实体间的几何距离。最后,我们还提供了数学证明,从理论上证明我们的模型可以处理知识图谱中复杂的逻辑关系。广泛的实验结果和分析表明,在四个标准公开的知识图谱补全数据集上,我们模型明显优于之前的模型。
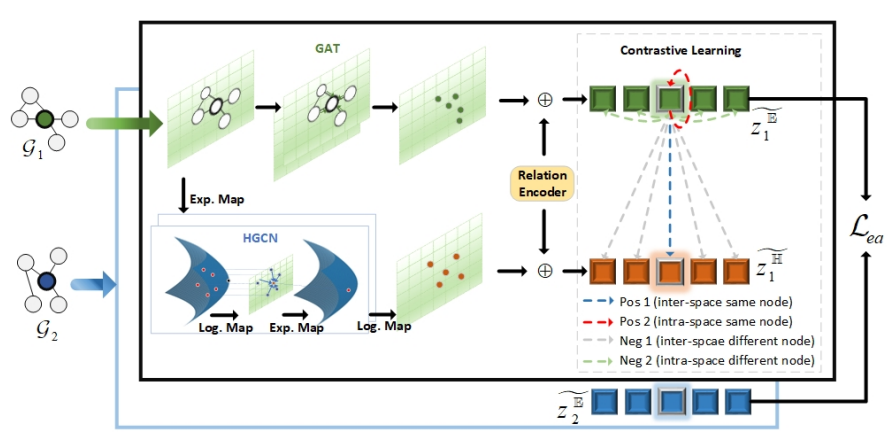
Unifying Dual-Space Embedding for Entity Alignment via Contrastive Learning
作者:王存达,王炜华*,梁秋雨,飞龙,高光来
单位:内蒙古大学
摘要:实体对齐任务是匹配不同知识图谱所指代的现实世界的相同实体,基于GNN的实体对齐在欧氏空间取得优异的结果。然而,知识图谱中包含了复杂的结构,例如局部结构信息和层次结构信息,单一的空间无法有效学习复杂结构信息。因此,我们提出一种使用对比学习统一双空间嵌入的实体对齐(UniEA)方法。具体来说,我们在欧氏空间和双曲空间分别使用不同图神经网络获得不同空间的嵌入,再将双曲空间嵌入投影到欧氏空间,利用对比学习学习不同空间的互信息。此外,为了解决相似实体嵌入距离相近,我们再次使用对比学习,将相似的邻居实体推开,避免相似实体引起的错误对齐。
C3LRSO: A Chinese Corpus for Complex Logical Reasoning in Sentence Ordering
作者:郭晓涛,李江,苏向东*,张富军
单位:内蒙古大学
摘要:句子排序任务(Sentence Ordering)旨在把一组无序句子重新整理成语义连贯且逻辑一致的序列。以往工作多借助预训练语言模型开展,取得显著成功。然而,现有的句子排序语料大多集中于英语,针对非英语语言的综合基准数据集却极为匮乏。同时,现有语料常在段落中插入特定标记,这在不经意间使句子间的逻辑顺序更为明显,进而削弱了模型在实际应用场景中处理真正无序句子的能力。为解决上述局限,我们开发了C3LRSO,首个高质量的中文句子排序数据集。它以提供无人工分割线索的无序句子为特色,克服了上述缺陷。此外,鉴于大语言模型在自然语言处理任务中的卓越表现,我们利用此数据集针对该任务对这些模型予以评估。我们还创新性地提出了一种简洁高效的无参数方法,该方法在本任务中表现优于现有的各类方法。实验证实了该语料所具有的挑战性,以及我们所提方法具有竞争力的性能。
GL-GAN: Perceiving and Integrating Global and Local Styles for Handwritten Text Generation with Mamba
作者:王一明,魏宏喜*,王恒,孙诗文,贺超
单位:内蒙古大学
摘要:手写文本生成(Handwriting Text Generation, HTG)旨在通过模仿特定书写者来合成手写样本,在手写识别领域应用广泛,因此具有重要的研究价值。然而,当前HTG研究面临一个主要问题:现有手写样本生成模型缺乏感知和整合书写风格的能力,这影响了所生成样本的真实感。本工作提出了一种新的手写样本生成模型(GL-GAN),通过所设计的基于状态空间模型和卷积神经网络的混合风格编码器,提取手写样本的全局风格与局部风格;并采用一个动态特征增强模块,有效去除全局风格与局部风格中的冗余特征,以自适应方式实现全局风格与局部风格的融合。所提出的GL-GAN模型在两个广泛使用的手写数据集上进行对比实验,结果表明所提出模型的性能达到了当前最优。
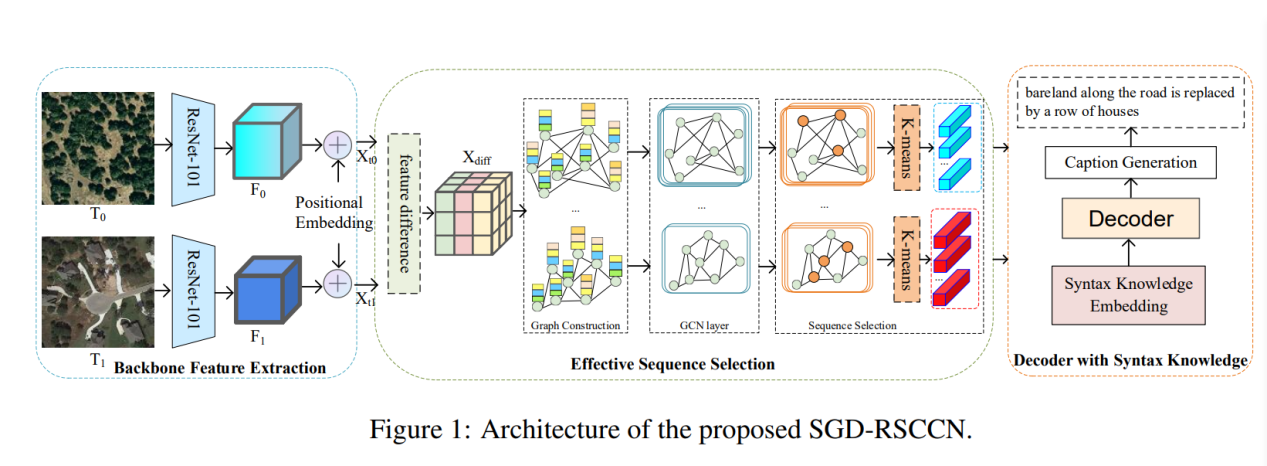
Scene Graph and Dependency Grammar Enhanced Remote Sensing
Change Caption Network (SGD-RSCCN)
作者:孙巧丽,王燕*,宋晓宇(外)
单位:内蒙古大学
摘要:随着遥感技术的不断进步,获取高分辨率、多时相、多光谱影像变得越来越容易。这些图像携带了丰富的地物信息。然而,如何有效地从复杂的图像数据中提取有用信息并将其转化为可理解的语义描述仍然是一个挑战。为了解决这些问题,我们提出了一种场景图和依赖语法增强的遥感变化描述网络(SGD-RSCCN),以提高遥感图像中变化信息提取和描述的准确性和自然度。该网络通过结合先进的视觉分析技术和自然语言处理技术,不仅优化了对复杂场景理解不足的问题,而且增强了对动态变化的捕捉能力,从而生成更准确、流畅的自然语言描述。此外,我们还提出了基于先验知识的解码器,进一步提高了描述的可读性和可理解性。在LEVIR-CC和Dubai-CC数据集上的大量实验验证了该方法在生成准确、真实的描述方面的优势。